
When Marcus, a conversion rate optimisation manager at a mid-sized SaaS company, ran what he thought was his most rigorous A/B test of the year, the results looked clean. Variant B, a simplified headline and a shorter form, outperformed the control by 22% over four weeks. His team celebrated. The change was shipped.
Three months later, conversion rates had drifted back to where they started. His head of growth asked him to investigate. What Marcus discovered unsettled him far more than the dip itself.
The visitors arriving at his landing page in the weeks after the test concluded were not the same visitors who had participated in it. The control period had captured a significant share of traffic from traditional Google organic searches. The post-launch period, without anyone noticing, had seen a sharp rise in referrals from AI platforms, ChatGPT, Perplexity, Google’s AI Overviews. Those visitors arrived with different knowledge, different expectations, and different behaviour than the population Marcus had optimised for.
His winning variant had been designed for people who needed persuading. The new audience had already been persuaded before they clicked. The test had given him a confident answer to a question that was no longer being asked.
This is the quiet crisis sitting at the centre of modern CRO. A/B testing, as most teams practise it, was built for a stable traffic environment. The assumption underneath every test is that the visitors in your control group and the visitors in your treatment group are drawn from the same underlying population, and that this population remains reasonably consistent over time. When that assumption holds, the statistical machinery works as intended. When it breaks, the results are worse than useless, they are confidently wrong.
AI-mediated search is breaking that assumption, not occasionally, but structurally and continuously.
The Foundation A/B Testing Was Built On
To understand why the problem is so serious, it helps to start with what A/B testing actually requires in order to function correctly.
The logic of a randomised controlled experiment rests on one central premise: that the only systematic difference between your control group and your treatment group is the variation you introduced. Everything else, visitor intent, prior knowledge, device type, buying stage, emotional state, should be distributed roughly equally across both groups by virtue of random assignment. This is what allows you to attribute any difference in outcomes to the change you made, rather than to a pre-existing difference in the people who saw each version.
For most of the history of web experimentation, this assumption held well enough. Organic traffic arriving through keyword searches was reasonably homogeneous. A visitor searching for “project management software” in 2019 and a visitor searching for the same phrase the following week were, on average, at a similar stage of the buying journey, carrying similar levels of prior knowledge, and arriving with broadly similar intent. Randomising them into control and treatment groups produced two populations that were genuinely comparable.
That world is changing rapidly. As we explored in our earlier piece on how AI search is reshaping CRO, the visitors reaching your website today are not a homogeneous group. Some arrive through traditional organic search, largely uninformed and in early discovery mode. Others arrive via AI referrals from ChatGPT, Perplexity, Claude, or Google’s AI Overviews, pre-educated, pre-filtered, and positioned much further down the buying funnel. Still others arrive from zero-click environments where they have already received a synthesised answer and are visiting your site specifically to verify a detail or confirm a decision.
These three visitor types behave differently on your page, respond differently to the same headline, and have entirely different thresholds for what constitutes a convincing reason to convert. Running a single A/B test across all three simultaneously is not rigorous experimentation. It is averaging across incompatible groups and calling the average a result.
What the Research Tells Us About Visitor Heterogeneity
The scale of this shift matters, and the numbers make it concrete.
Research from Semrush analysing 12.3 million website visits across 347 businesses found that AI search traffic converts at 14.2%, compared to Google organic traffic’s 2.8%, a difference of roughly five times (Semrush, 2025). Traffic referred from Claude converts at 16.8%. ChatGPT users view an average of 2.3 pages per session compared to just 1.2 for traditional organic visitors.
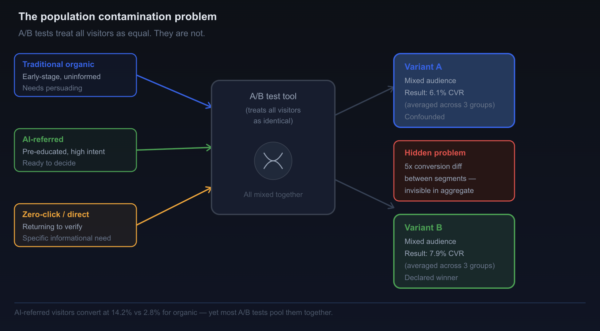
These are not marginal differences in behaviour. They represent fundamentally different visitor populations arriving on the same URL at the same time. When an A/B testing tool randomly assigns both a traditional organic visitor and a Claude-referred visitor to “treatment” or “control,” it is treating them as interchangeable units in the same experiment. They are not.
The consequences of this contamination have been documented in the experimentation literature under the broader concept of population drift. Montgomery et al. (2004) identified population heterogeneity as one of the primary sources of experimental invalidity in online testing, noting that even small systematic shifts in the composition of incoming traffic could invalidate effect estimates derived from randomised trials. What they described as an occasional risk has, in the current environment, become a permanent structural feature.
A 2023 paper by Larsen et al. in The Annals of Applied Statistics formalised the problem further, demonstrating that A/B tests run under conditions of treatment effect heterogeneity, where different subpopulations respond differently to the same intervention, produce average treatment effects that are statistically precise but practically misleading. The test tells you what worked on average across a mixed population, but if that population is heterogeneous enough, the average might not reflect the optimal approach for any specific segment within it.
In the AI search era, treatment effect heterogeneity is not an edge case. It is the default condition.
The Temporal Contamination Problem
There is a second dimension to the breakdown that is equally serious and less frequently discussed: the problem of temporal contamination.
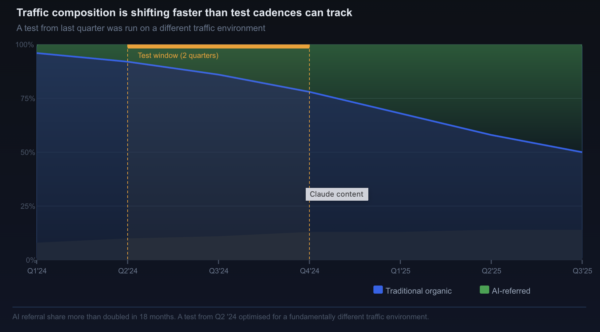
Standard A/B testing protocols assume that the test period is representative of the broader traffic environment in which a winning variant will eventually be deployed. If you run a test in January and observe a 15% lift for Variant B, you expect that Variant B will deliver approximately 15% more conversions when it goes live for all traffic going forward.
This expectation depends on the traffic environment remaining reasonably stable between your test period and your post-launch period. In a world where AI platform adoption is growing at scale and the composition of search traffic is shifting month by month, that stability no longer exists.
Consider the timeline. Google’s AI Overviews now appear in approximately 13% of all U.S. desktop searches, a figure that doubled between January and March 2025 (Search Engine Land, 2025). Perplexity, ChatGPT, and Microsoft Copilot collectively generated 1.13 billion referral visits in June 2025 alone, a 357% increase from the same period the previous year (TechCrunch, 2025). These are not incremental changes in traffic composition. They represent a rapid structural shift in who is arriving at websites, and from where.
A test conducted in September 2025 and a test conducted in January 2026 are not operating in the same traffic environment. A result validated in one environment cannot be reliably extrapolated to the other. The winning variant from last quarter may no longer be optimal for the visitor mix you have this quarter, not because you implemented it incorrectly, but because the population of people arriving on your page has changed beneath it.
This is a specific instance of what statisticians call temporal non-stationarity, a condition where the data-generating process is itself changing over time. Kohavi et al. (2020), in their comprehensive treatment of online experimentation in Trustworthy Online Controlled Experiments, identify temporal non-stationarity as one of the most commonly overlooked threats to A/B test validity, noting that practitioners frequently underestimate the rate at which digital traffic environments evolve.
The AI-driven transformation of search is not a slow drift. It is an accelerating shift, and traditional testing cadences, run a test for four weeks, ship the winner, move on, are not designed to account for it.
The Sample Ratio Mismatch You Are Not Detecting
Beyond population drift and temporal contamination, AI-mediated traffic introduces a subtler but equally damaging problem: structural imbalances in how visitors from different sources distribute across test variants.
In a well-run A/B test, visitors should be randomly and evenly distributed between control and treatment. If your test is set to a 50/50 split, roughly half of all visitors should see each variant. When the actual split deviates significantly from the intended split, this is known as a sample ratio mismatch (SRM), and it is a reliable indicator that something in the experimental setup is not functioning as intended. Any SRM should immediately invalidate the test results.
The standard causes of SRM, bot traffic, redirect delays, inconsistent cookie assignment, are well documented. Less documented is the way AI referral traffic can introduce indirect SRM through correlation between traffic source and test exposure.
Visitors arriving from AI platforms often carry session characteristics that interact with how testing tools assign variants. They tend to have more complex referral chains, longer delay times between intent formation and click, and different device profiles than traditional organic visitors. If these characteristics happen to correlate with the timing or sequencing of variant assignment in your testing tool, the result is a non-random distribution of AI-referred versus traditionally-referred visitors across your test arms.
You may not detect this as an SRM in the classical sense, because the raw split may look balanced. But the composition of that split, which kinds of visitors ended up in which arm, can be systematically skewed in ways that corrupt your results without triggering any automatic alerts.
Dmitriev and Wu (2016) described this phenomenon in their foundational paper on SRM in large-scale online experiments at Microsoft, noting that subtle assignment correlations could produce biased results even when headline traffic splits appeared balanced. The arrival of AI referral traffic as a systematically distinct cohort intensifies this risk considerably.
Why Statistical Significance Is No Longer Sufficient
The most dangerous aspect of A/B testing failure in a heterogeneous, dynamic traffic environment is that the tests continue to produce results that look rigorous.
Your p-values still reach the thresholds you set. Your confidence intervals still narrow appropriately given your sample size. Your testing platform still displays a green checkmark and declares a winner. Nothing in the output signals that the experiment was contaminated by population heterogeneity or temporal drift. The machinery continues to function, and its outputs continue to look credible.

This creates a false sense of security that may be worse than acknowledged uncertainty. A test result that is known to be unreliable invites scrutiny and caution. A test result that appears statistically valid but is built on a broken assumption tends to get shipped and replicated until someone notices, months later, that the lift never materialised at scale.
Lukas et al. (2022), writing in the Journal of Marketing Research, demonstrated this failure mode empirically: experiments run under conditions of heterogeneous treatment effects can achieve high statistical power while still producing directionally incorrect recommendations for specific sub-segments. Their conclusion was direct, statistical validity, as traditionally measured, is a necessary but insufficient condition for practical validity in heterogeneous traffic environments.
Rethinking what “a valid test result” actually means in the current landscape is not optional for serious CRO practitioners. It is foundational.
What Needs to Change: A Framework for AI-Era Experimentation
None of this means that experimentation is dead. What it means is that the specific implementation of experimentation that most teams are currently running needs to be substantially updated. The following framework addresses the core failure points.
Segment before you test, not after
The most direct solution to population heterogeneity is to stop running single experiments across your entire visitor pool and start running experiments within clearly defined visitor segments. Before launching any test, explicitly define which population the test is intended to inform. AI-referred visitors are one segment. Traditional organic visitors are another. Returning visitors who arrived via direct navigation are a third.
Testing within segments rather than across them eliminates the averaging problem. A headline that converts AI-referred visitors more effectively and a headline that converts informational browsers more effectively might be the same headline, or they might be entirely different. The only way to know is to test within each population separately and compare the results.
This approach is technically achievable with most modern testing platforms, but it requires a deliberate instrumentation investment. You need reliable traffic source attribution at the session level, including the ability to distinguish AI referral traffic from traditional organic traffic. As we noted in our piece on measuring the true impact of AI-driven search on digital sustainability, the measurement infrastructure that makes sustainability reporting possible is closely related to the infrastructure that makes intelligent segmentation possible. Building one builds the other.
Shorten your test windows and monitor for population drift
Four-week test windows made sense when traffic composition was relatively stable. In a rapidly shifting AI search environment, they represent an unacceptable amount of accumulated drift. Shorter test windows, one to two weeks as a default, with pre-specified stopping rules, reduce the exposure to temporal non-stationarity.
Alongside shorter windows, implement continuous monitoring of the composition of your test traffic, not just the volume. Track the ratio of AI-referred to organically-referred visitors in each test arm over time. If that ratio shifts significantly during the test period, treat it as a contamination event and restart the experiment rather than continuing to accumulate potentially invalid data.
Test for interaction effects, not just main effects
Traditional A/B testing asks: does Variant B convert better than Variant A? AI-era testing should ask: does Variant B convert better than Variant A for a specific visitor segment, and are there differential effects across segments that the aggregate result is hiding?
This reframe moves from simple hypothesis testing toward factorial or interaction-based experimental designs. These are more complex to set up and require larger sample sizes to achieve adequate statistical power. But they produce results that are genuinely actionable at the level of specific visitor populations, rather than results that are optimised for an average visitor that may not represent your most valuable cohorts.
Treat AI citation as a pre-experiment variable
If your brand appears in AI-generated answers, in Google AI Overviews, in Perplexity summaries, in ChatGPT responses, the content of those appearances influences the expectations your visitors carry when they arrive. This is a pre-experiment variable that affects how your variants will be received, but it is entirely outside the control of your testing tool.
Before running any significant landing page experiment, audit what AI platforms are saying about you, as we outlined in our framework for intent-matched CRO. The AI description of your product is effectively a part of your landing page experience that visitors consume before the test begins. A variant that aligns with that description will receive a reception bias in its favour. A variant that contradicts it may perform poorly for reasons that have nothing to do with its intrinsic quality.
Adopt Bayesian experimentation methods
Frequentist A/B testing, the dominant paradigm in most platforms, produces results that are poorly suited to dynamic, heterogeneous environments. The binary framing of “statistically significant win” versus “no result” is designed for stable conditions where you need a definitive answer before taking action.
Bayesian experimentation provides a more appropriate tool for uncertain, shifting environments. It produces probability distributions over outcomes rather than binary conclusions, allows for continuous updating as new data arrives, and naturally accommodates the possibility that the right answer for one population differs from the right answer for another. Raftery et al. (2020) demonstrated in a large-scale applied study that Bayesian A/B methods outperformed frequentist counterparts in environments with high population variance, producing more reliable lift estimates with less exposure to temporal drift contamination.
Major platforms including Google Optimize’s successor products and VWO have begun integrating Bayesian frameworks, but most teams continue to use frequentist defaults without considering whether those defaults remain appropriate.
The Parallel Shift Happening in Test Design
There is one more dimension of failure worth naming, because it operates at the level of what teams decide to test in the first place, rather than how they analyse results.
Traditional CRO test roadmaps are typically built from heuristics: button colours, headline length, form fields, hero images. These are surface-level optimisations designed to remove friction for a visitor who is broadly considering your offer. They assume that the primary conversion barrier is uncertainty or inertia, that visitors need to be nudged, simplified for, or reassured.
AI-referred visitors, who arrive already past the uncertainty and inertia phase, are not primarily blocked by these friction points. They are blocked by specificity gaps, the absence of information that confirms your solution is the right fit for their precise context, as we established in our CRO piece on intent-matching in the AI search era.
Testing headline capitalisation on a page where the conversion barrier is actually a missing use-case match is an experiment that optimises the wrong variable. The result, even if statistically valid, answers the wrong question.
The shift required is from testing presentation to testing content. Do visitors convert at higher rates when you show them a case study from their specific industry? When you name their specific job title in the opening paragraph? When you lead with pricing rather than value proposition? These tests require different creative assets and longer build cycles, but they address the actual conversion barrier for the visitor population that increasingly matters.
The Acara Strategy case study, published by Everything Green in December 2025, demonstrated that conversion efficiency and environmental efficiency are the same objective: every visitor who fails to accomplish their goal represents energy burned for zero outcome. The same principle applies to testing efficiency. Every test that answers the wrong question for the wrong population consumes experimentation resources, engineering time, traffic, opportunity cost, while producing results that do not improve actual conversion performance.
A Practical Checklist for Modern Experimentation
For teams that want to update their practices without rebuilding their entire experimentation programme from scratch, these five steps represent a workable starting point.
First, add AI referral source detection to your analytics setup. Most analytics platforms can be configured to identify sessions originating from ChatGPT, Perplexity, Claude, and similar sources through referral domain tagging. This is a foundational data infrastructure step that unlocks every subsequent improvement.
Second, add traffic source composition as a standard metric in your experiment dashboards. Before declaring any test result valid, verify that the ratio of AI-referred to organically-referred traffic was consistent across both test arms and stable over the test period.
Third, run your next significant test as a segmented experiment rather than a single aggregate test. Choose one traffic segment, AI-referred visitors are a natural starting point given their distinct behaviour, and run the test within that segment while monitoring behaviour in other segments separately. Compare the results.
Fourth, review your test roadmap through the lens of intent-stage alignment. For each planned test, ask: does this test address a conversion barrier relevant to late-funnel, pre-educated visitors, or is it designed for early-funnel visitors who are less and less representative of your incoming traffic?
Fifth, set up a lightweight population monitoring alert. When the share of AI-referred traffic in your site’s overall mix shifts by more than 10 percentage points over a rolling 30-day period, treat it as a signal to review the validity of any experiments currently in progress.
None of these steps require new tooling. All of them require the kind of deliberate attention to measurement quality that separates experimentation programmes that produce durable results from those that produce impressive dashboards and underwhelming outcomes.
Conclusion
Marcus eventually rebuilt his testing programme around segmented experiments. His first segmented test, run separately for AI-referred visitors and traditional organic visitors, produced two different winning variants. The one designed for AI-referred visitors, featuring specific use-case confirmation and direct-access pricing, outperformed the generic winner by 31% within that cohort. The one designed for early-funnel organic visitors looked almost identical to his original winning variant.
The aggregate test would never have surfaced this insight. Averaged across both populations, the differences between variants would have partially cancelled out, producing a result that was confident, statistically valid, and operationally useless.
The fundamental shift required in CRO experimentation is not a new tool or a new platform. It is an updated mental model: one that treats your incoming visitor population as heterogeneous by default, that recognises the traffic environment as a dynamic system that is changing faster than traditional testing cadences can track, and that holds statistical significance to a higher practical standard than a p-value and a green checkmark.
A/B testing remains one of the most powerful tools in digital marketing. But a powerful tool operated under the wrong assumptions produces wrong answers with great confidence. In an environment where AI is reshaping who arrives at your website and what they already know when they get there, the assumptions need to catch up.
FAQ
Q: Is A/B testing no longer useful in an AI search environment?
A/B testing remains highly valuable, but the specific practices most teams use need updating. The problem is not the experimental method itself but the assumption that all incoming visitors are drawn from a single homogeneous population. Segmenting experiments by visitor intent and traffic source, shortening test windows to reduce temporal drift, and testing content and specificity rather than just surface presentation all restore the validity that AI-driven traffic heterogeneity has eroded. The teams that update their approach will get more from experimentation, not less.
Q: How do I identify which of my visitors are arriving via AI referral?
Most web analytics platforms, including Google Analytics 4 and Mixpanel, can be configured to flag sessions originating from AI platforms through referral domain recognition. Sessions from chatgpt.com, perplexity.ai, claude.ai, and related domains can be tagged and segmented. Google Search Console is beginning to surface AI Overview-influenced organic sessions separately in some reporting views. The infrastructure for this segmentation already exists, it simply needs to be deliberately configured.
Q: What sample size do I need to run a segmented A/B test on AI referral traffic only?
This depends on your current volume of AI-referred visitors and the minimum detectable effect you are targeting. If AI referral traffic represents a small percentage of your total traffic, segmented testing within that cohort may require extending your test window or lowering your statistical power threshold. Bayesian methods are particularly useful here: they allow for valid inference with smaller sample sizes by expressing results as probability distributions rather than binary yes/no conclusions, and they update continuously as traffic accumulates.
Q: Won’t AI referral traffic grow to the point where I can simply test on it directly?
In many categories and for many brands, yes. Adobe’s 2025 analytics data found that AI-referred visitors already show a 23% lower bounce rate and 41% more time on site than traditional organic visitors (Adobe, 2025). As AI referral volumes grow, segmented testing within that cohort becomes increasingly practical as a standard approach rather than a supplementary one. Building the measurement infrastructure now means being positioned to act on that data as volumes increase, rather than scrambling to retrofit it later.
Q: How does this connect to the environmental cost of running my website?
The connection is direct. As the Acara Strategy case study demonstrated, 74% of a website’s carbon emissions come from visitors’ devices rendering pages. Every test that produces a misleading result and leads you to deploy a suboptimal variant for your actual visitor population results in more visitors failing to convert, and those failed visits are both a revenue loss and an environmental cost. Wasted visits burn device-side energy for no outcome. Testing that correctly accounts for your visitor population produces higher conversion rates, lower bounce rates, and a smaller carbon footprint per meaningful interaction.
Q: Should I switch entirely to Bayesian A/B testing?
Bayesian methods offer genuine advantages in dynamic, heterogeneous environments, particularly their ability to express uncertainty as a probability distribution, to update continuously, and to avoid the binary forced-choice of frequentist significance thresholds. However, the most important change is not which statistical framework you use but whether your experimental design accounts for visitor population heterogeneity in the first place. Correctly segmented frequentist tests will outperform poorly segmented Bayesian tests. The two improvements, better segmentation and better statistical methods, are complementary rather than alternatives.
References
Dmitriev, P., & Wu, X. (2016). Measuring metrics. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2039–2048.
Kohavi, R., Tang, D., & Xu, Y. (2020). Trustworthy online controlled experiments: A practical guide to A/B testing. Cambridge University Press.
Larsen, N., Stallrich, J., Sengupta, S., Deng, A., Kohavi, R., & Stevens, N. T. (2023). Statistical challenges in online controlled experiments: A review of A/B testing methodology. The American Statistician, 78(2), 135–149.
Montgomery, A. L., Li, S., Srinivasan, K., & Liechty, J. C. (2004). Modeling online browsing and path analysis using clickstream data. Marketing Science, 23(4), 579–595.
Raftery, T., Beasley, J., & Vermeulen, N. (2020). Bayesian A/B testing for business decisions. Applied Stochastic Models in Business and Industry, 36(5), 765–783.
Search Engine Land. (2025, March). Google AI Overviews now show on 13% of searches: Study.
Semrush. (2025). We studied the impact of AI search on SEO traffic.
TechCrunch. (2025, July 25). AI referrals to top websites were up 357% year-over-year in June, reaching 1.13B.